
大多数系统在数据库存的都是系统的状态数据,比如一个用户表可能会存用户的姓名、头像、个性签名等信息。如果只存状态数据的传统模式会有什么问题呢?
问题起源
假设你公司做了一个系统,并正式上线了。经过一周的推广,老板问你要一些用户的行为数据。老板想知道所有用户平均修改个性签名的次数。
对于传统的数据库设计,当用户修改个性签名,会执行类似如下的 SQL 语句:
UPDATE Users SET Sign='Talk is cheap, show me the code.' WHERE Id=123
问题是目前数据库没有记录用户修改密码次数的字段。于是,为了更快的实现老板的需求,你需要给数据库的用户表增加这样一个字段。用户每次修改个性签名的时候,这个字段值加一。
这样虽然很好的解决了问题,但如果这种需求越来越多,比如老板又问你要所有用户平均修改密码的次数,就会有一些明显的问题:
- 应对这种需求需要修改代码,重新测试和发布。
- 需要修改数据库,会使得数据库设计越来越复杂。
- 增加的字段依然是状态数据,无法反映某时间段用户的行为。比如无法获取某用户上次修改密码的时间、每年修改了多少次密码等信息。
上面用户的个性签名、密码修改次数的例子算是简单的需求,增加字段、修改代码还可以应付。但需求稍微变换一下,复杂一点,比如要分析某商品在用户购物车中变化的情况,如什么时间点添加这个商品到购物车的用户最多、当用户从购物车移除该商品的同时购物车中有哪些竞品等。这种需求带来的修改,会使数据库设计和系统变得无比复杂,产生的工作量也是巨大的。
可见,随着系统不断扩大,业务需求越来越多样化,这种数据库存储状态数据的传统模式就会越发捉襟见肘了。
面对这种“痛”,事件溯源可能是一剂良方。
一剂良方
事件溯源(ES,Event Sourcing),字面上理解就是使任何对数据的修改都可追溯。
事件溯源是一种设计模式。相对于传统的在数据库中存储系统的状态,事件溯源在数据库中存储的是系统发生的事件。
举个例子,当用户在系统中注册后,一个UserCreated的事件就被存储了。然后,当用户修改了密码,一个UserChangedPassword的事件就被存储了。对于这个用户而言,通过事件溯源设计模式,系统可以知道该用户的一举一动。比如按照时间线,某个用户的事件可能是这样的:
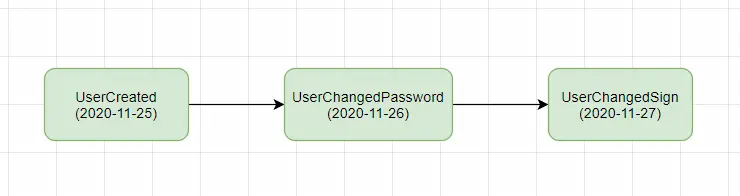
这样对于前文用户平均修改个性签名次数的需求,就可以轻松应对了。只需要查询事件为UserChangedPassword的数量再除以用户总数即可。
事件溯源在现实世界中更接近人们的思维习惯,比如当有人问你今天过得怎么样时,你不会告诉他们今天你的体重是多少、吃了几顿饭(状态数据),而会告诉他们发生了什么有趣的事情(事件)。所以对系统来说,也更容易建模。
适用范围
事件溯源适用于数据分析,可以生成各种维度的报表,帮助你更深入地了解数据;可以提供审计日志,帮助你准确地知道系统是如何从一个状态变成另一个状态的。比如你在银行存了一千万,隔了一年后发现账户余额只有一百块。事件溯源就可以告诉你,你是如何一步一步从一个千万富翁变成穷光蛋的。
听上去不错,但事件溯源也不是包治百病的万能药。
事件溯源会给系统增加额外的复杂性。往往用传统方式可以简单快速完成的增、删、改功能,使用事件溯源就会多绕几步。它通常需要与 CQRS (Command Query Responsibility Segregation,命令查询职责分离) 结合使用,这对开发人员而言,学习成本更高。
如果是不需要审计日志的小规模系统,使用事件溯源就会得不偿失。如果团队中没有在这方面有足够的经验的开发者,也不要轻易在生产环境中使用它。没有精钢钻,不揽瓷器活。