原文:https://bit.ly/2UMiDLb
作者:Jon P Smith
翻译:王亮
声明:我翻译技术文章不是逐句翻译的,而是根据我自己的理解来表述的。其中可能会去除一些本人实在不知道如何组织但又不影响理解的句子。
本文将为你详细描绘 EF Core 从数据库中读取数据的“幕后”视图。我将揭开两种数据库读取方式的面纱:一个是普通的查询,另一个是使用 AsNoTracking 方法的非跟踪查询。我还将通过一个实验来演示我是如何解决我的一个客户遇到的性能问题。
我假设你对 EF Core 已经有了一定的认识,但在深入学习之前,我们先来了解一下如何使用 EF Core,以确保我们已经掌握了一些基本知识。这是一个“深入研究”的课题,所以我准备大量的技术细节,希望我的描述方式你能理解。
本文是“深入理解 EF Core”系列中的第一篇。以下是本系列文章列表:
- 当 EF Core 从数据库读取数据时发生了什么?(本文)
- 当 EF Core 写入数据到数据库时发生了什么?(敬请期待)
概要
- EF Core 有两种方法从数据库中读取数据(也称为查询):普通 LINQ 查询和包含 AsNoTracking 方法的非跟踪 LINQ 查询。
- 这两种方法查询的返回类(被称为实体类),它连接的其它的实体类(即所谓的导航属性)也被同时加载,但这两种法如何连接及连接的内容是不一样的。
- 普通查询接受的是 DbContext 执行读取时所有数据的副本——此时的实体类称为被跟踪。这允许加载的实体类参与数据库的更新操作。
- 普通查询还会有一些其它的复杂底层实现,称为关系修补(fixup),用于描述读入的实体类和其他被跟踪实体之间的连接关系。
- AsNoTracked 非跟踪查询没有副本,所以它没有被跟踪——这意味着它比普通查询更快。这也意味着它不会用于数据库的写操作。
- 最后,我将展示 EF Core 普通查询中一个鲜为人知的特性,以此作为示例,说明通过导航属性连接实体类的关系是多么智能。
EF Core 如何读取数据库数据
提示:如果你已经对 EF Core 有一定的认识,那么你可以跳过这一节,这部分只是一个如何读取数据库的例子。
为了能让你更好地理解,我先描述一个数据库结构,然后再给出一个简单的数据库读取示例。下面是一些基本表的结构和它们之间的关系。

这些表被映射到具有类似名称的类,例如 Book、BookAuthor、Author,这些类的属性名称与表的字段名称相同。由于篇幅有限,我不打算展开来讲这些类,但您可以在我的 GitHub 仓库[1]中查看这些类。
EF Core 读取数据库需要下面五部分:
- 数据库服务器,如 SQL server, Sqlite, PostgreSQL 等。
- 具有数据的数据库。
- 映射到数据表的类(称为实体类)。
- 一个继承 DbContext 的类,该类包含 EF Core 的配置。
- 最后,从数据库读取数据的命令。
下面的单元测试代码来自我的 GitHub 创库[2],展示了一个简单的示例,它从现有数据库中读取 4 个 Book 实体及其关联的 BookAuthor 和 Authors 实体。
[Fact]
public void TestBookCountAuthorsOk()
{
//SETUP
var options = SqliteInMemory.CreateOptions<EfCoreContext>();
//code to set up the database with four books, two with the same Author
using (var context = new EfCoreContext(options))
{
//ATTEMPT
var books = context.Books
.Include(r => r.AuthorsLink)
.ThenInclude(r => r.Author)
.ToList();
//VERIFY
books.Count.ShouldEqual(4);
books.SelectMany(x => x.AuthorsLink.Select(y => y.Author))
.Distinct().Count().ShouldEqual(3);
}
}
现在,如果我们将单元测试代码对应到上面的 5 部分,结果是这样的:
- 数据库服务器——第 5 行:我选择了一个 Sqlite 数据库服务器,在本例中是
SqliteInMemory.CreateOptions方法,它使用我的一个 NuGet 包 EfCore.TestSupport 创建了一个内存数据库(内存中的数据库对于单元测试非常有用,因为你可以为这个测试建立一个新的空数据库)。 - 具有数据的数据库——第 6 行:我将在下一篇文章介绍数据是如何写入数据库的,现在假设有一个数据库包含 4 本书信息,其中两本书的作者是同一个人。
- 实体类——代码里这里没有展示,但是你可以在这里查看这些类[1]。其中有一个 Books 实体类,通过一个名为 BookAuhor 的实体类多对多关联 Authors 实体类。
- 一个继承 DbContext 的类——第 7 行:EfCoreContext 类继承了 DbContext 类并配置了从类到数据库的映射关系(你可以在我的 GitHub 仓库[3] 中查看该类)。
- 从数据库读取数据的命令——第 10 到 13 行,这是一个查询:
- 第 10 行 — context 为 EfCoreContext 的实例,通过它访问你的数据库,
.Books表示您希望访问 Books 表。 - 第 11 行 — Include 被称为贪婪加载,它告诉 EF Core 当它加载 Books 时,也应该加载关联到的所有 BookAuthor 实体类。
- 第 12 行 — ThenInclude 是继续贪婪加载,它告诉 EF Core 当它加载一个 BookAuthor 时,它也应该加载关联到该 BookAuthor 的 Author 实体类。
- 第 10 行 — context 为 EfCoreContext 的实例,通过它访问你的数据库,
所有这一切查询出来是一个结果集,其中有普通属性,像 Books 的 Title 属性;有关联实体类的导航属性,像 Books 的 AuthorsLink 属性。
这个示例称为查询或读取,也是四种数据库访问类型之一,即 CRUD(新增、读取、更新和删除)。我将在下一篇文章中介绍新增和更新。
EF Core 如何表示读取的数据
当你查询数据库时,EF Core 会将数据库返回的数据转换为实体类并填充导航属性的值。在本节中,我们将研究两种类型的查询步骤——普通查询(即没有 AsNoTracking 方法,也称为读写查询)和添加了 AsNoTracking 方法的非跟踪查询(称为只读查询)。
我们先来看一下最初 LINQ 语句是如何转换成数据库相应的查询命令然后返回数据的。对于我们将要看到的两种类型的查询来说,这是很常见的操作。关于查询的第一部分,请参见下图。

有一些非常复杂的代码将你的 LINQ 转换为数据库查询命令,但这些内部细节我们不必关心。如果你的 LINQ 不能被翻译,你会从 EF Core 得到一个异常消息,其中包含类似“不能被翻译”的描述词语。此外,当数据返回时,像 Value Converters[4] 这样的特性可能会调整数据。
本节展示了查询的第一部分,其中 LINQ 被转换为数据库命令并返回所有正确的值。现在我们来看查询的第二部分,在这里 EF Core 获取返回值并将它们转换为实体类的实例,并填充导航属性。我们将分别看看两种类型的查询。
1. 普通查询(读写查询)
普通查询读取数据的方式可以修改数据并更新到数据库,这就是我将其称为读写查询的原因。它不会自动更新数据(请参阅下一篇文章,了解如何写入数据库)。如果你要更新数据,你的查询必须是读写查询。
我在介绍中给出的示例执行的是一个普通读写查询,读取带有 AuthorsLink 实例的示例。下面是该示例的查询部分的代码:
var books = context.Books
.Include(r => r.AuthorsLink)
.ThenInclude(r => r.Author)
.ToList();
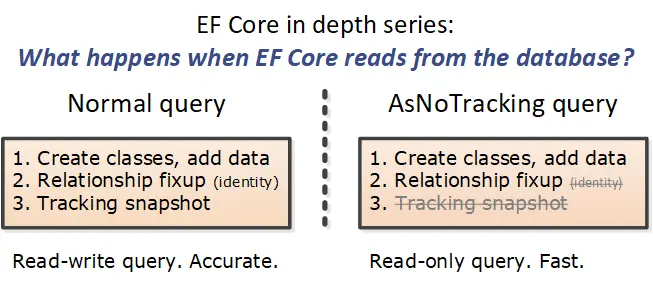
然后 EF Core 通过三个步骤将这些值转换并填充含有导航属性的实体类。下图显示了这三个步骤以及生成的实体类及其导航属性的实体类。

让我们来分析一下这三个步骤:
- 创建类并填充数据。它接受数据库返回的值,并填充非导航(称为标量)属性、字段等。在 Book 实体类中,是 BookId(主键)、Title 等属性——参见上图左下角浅蓝色矩形。
- 修补关联关系。首先是填入主键和外键的信息,它们定义如何相互关联数据。然后,EF Core 使用这些键设置实体类之间的导航属性(如图中蓝色粗线所示)。这个关系的修补所需的信息不仅是查询读入的实体类,它还会查看 DbContext 中跟踪的每个实体,并填充导航属性。这是一个强大的功能,但你的被跟踪实体越多,所需消耗时间也越多——这就是为什么需要 AsNoTracking 来实现更快的查询。
- 创建跟踪快照。跟踪快照是返回给用户的实体类的一个副本,加上它所隐藏的与每个实体类的关联关系——若一个实体处于被跟踪状态,这意味着它将会发生修改并会写入到数据库中。
2. 非跟踪查询(只读查询)
非跟踪查询,即使用 AsNoTracking 方法的查询,是一个只读查询。这意味着,当 SaveChanges 方法被调用时,你读取的任何内容都不会被写入数据库。非跟踪查询的查询效率更高,在下一节中,我将介绍非跟踪查询以及与普通查询的其他区别。
在前文的示例之后,我修改了查询代码,添加了下面的 AsNoTracking 方法(请看第 2 行):
var books = context.Books
.AsNoTracking()
.Include(r => r.AuthorsLink)
.ThenInclude(r => r.Author)
.ToList();
这里的 LINQ 查询只有上面的普通查询的前两个步骤(没有第三个步骤)。下图显示了 AsNoTracking 查询的步骤。
![]()
步骤如下:
- 创建类并填充数据。它接受数据库返回的值,并填充非导航(称为标量)属性、字段等。在 Book 实体类中,是 BookId(主键)、Title 等属性——参见上图左下角浅蓝色矩形。
- 修补关联关系。首先是填入主键和外键的信息,它们定义如何相互关联数据。然后,EF Core 使用这些键设置实体类之间的导航属性(如图中蓝色粗线所示)。这个关系的修补所需的信息不仅是查询读入的实体类,它还会查看 DbContext 中跟踪的每个实体,并填充导航属性。这是一个强大的功能,但你的被跟踪实体越多,所需消耗时间也越多——这就是为什么需要 AsNoTracking 来实现更快的查询。
普通查询和非跟踪查询的区别
现在让我们比较这两种查询比较明显的区别。
非跟踪查询查询的性能更好。使用非跟踪查询查询的主要原因是性能。非跟踪查询查询表现为:
- 稍微快一点,使用的内存稍微少一点,因为它不需要创建跟踪快照。
- 避免没有必要的跟踪快照可以提高 SaveChanges 的性能,因为它不必检查跟踪快照以查找更改。
- 稍微快一点,因为修补关联关系时没有所谓的身份解析。这就是为什么你会得到两个具有相同数据的 Author 实例。
非跟踪查询修补关联关系时只链接查询中的实体。在普通查询中,我已经说过修补关联关系时连接的是查询中的实体和当前跟踪的实体,但是非跟踪查询只修补查询中的实体关系。
非跟踪查询并不总是代表数据库关系。这两种类型查询之间的关系修补的另一个区别是,非跟踪查询关系修补更快,它不需要标识的解析。这可以为数据库中的同一行生成多个实例——见上图右下角蓝色的 Author 实体和注释。如果只是向用户显示数据,那么这种差异并不重要,但是如果具有业务逻辑,那么多个实例不能正确反映数据的结构,就可能会有问题。
对层级数据有用的关系修补特性
关联关系修补的步骤是非常智能的,特别是在普通查询中。下面我想向你展示我是如何利用关系修补的特性来解决一个客户项目中的性能问题的。
我曾在一家公司工作,那里的许多数据处理都是层次化结构的,即数据具有一系列深度不确定的关联关系。问题是我必须先解析整个层次结构,然后才能呈现这些数据。我最初是通过贪婪的方式加载前两个层级,然后显式地加载更深的层级来实现这一点的。它可以工作,但是性能非常慢,并且数据库因大量单数据库访问而超载。
这不得不让我思考解决办法,如果普通查询的关系修补那么智能的话,它能帮助我提高查询的性能吗?它可以!让我给你举一个公司员工的例子。下图显示了我们想要加载的公司的层次结构。

你可以接龙式地使用 .Include(x => x.WorksForMe).ThenInclude(x => x.WorksForMe)… 等等来加载所需的层级信息,但结果是一个 .Include(x => x.WorksForMe) 就够了。因为 EF Core 的关系修补为你做了剩下的事情,这一点很惊奇,但也很有用。
例如,如果我想查询角色为 Development 的所有员工(每个员工都有一个名为 WhatTheyDo 的属性和名为 Role 的属性,该 Role 包含他们工作的部门),我可以这样编写代码:
var devDept = context.Employees
.Include(x => x.WorksFromMe)
.Where(x => x.WhatTheyDo.HasFlag(Roles.Development))
.ToList();
这将创建一个查询,用于加载角色为 Development 的所有员工,并且在员工实体类上修补与 WorksFoMe 导航属性(集合)和 Manager 导航属性(单个)的关系。通过只执行一个查询,既提高了查询花费的时间,又减少了数据库服务器上的负载。
总结
你已经看到了两种类型的查询,我称之为 a)普通的读写查询,和 b) 非跟踪的只读查询。对于每一种查询类型,我都向你展示了 EF Core “幕后”是如何读取数据并展示的。他们工作方式的不同也表现出他们的优势和劣势。
非跟踪查询是只读查询的解决方案,因为它比普通读写查询更快。但是您应该记住关系修补的机制,它可以在数据库只有一个关系的情况下创建类的多个实例。
普通的读写查询是查询跟踪实体的解决方案,这意味着你可以在创建、更新和删除数据时使用它们。普通的读写查询确实会占用更多的时间和内存资源,但是有一些有用的特性,比如自动链接到其他被跟踪的实体类实例。
我希望这篇文章对您有用。祝你编程快乐!
[1]. https://bit.ly/2MXK3ZY
[2]. https://bit.ly/2Yza7QQ
[3]. https://bit.ly/2Y0UORO
[4]. https://bit.ly/2YEyg8j